Doing bayesian data analysis
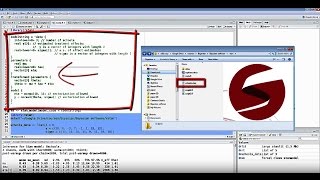
I have soooo many textbooks on bayesian inference, and while they are useful, a lot of them are emphasise theory and pay little attention to practice. Now read in simulated data as if it were a data file:mydata = ("")y = mydata[,c("y1","y2")]#----------------------------------------------------------------------------# the rest can remain unchanged, except for the specification of difference of# means at the very end. The book gradually climbs all the way to advanced hierarchical modeling methods for realistic data.

And jags computer programming code on ses have explicit purposes and guidelines for es step-by-step instructions on how to conduct bayesian data analyses in the popular and free software r and -year graduate students and advanced undergraduate students in statistics, data analysis, psychology, cognitive science, social sciences, clinical sciences and consumer sciences in r 1: what's in this book (read this first! Ellipselevel)*" level contour") ) abline(0,1,lty="dashed") # posterior ellipses: for ( stepidx in stepvec ) { points( ellipse( mcmcmat[ stepidx , paste0("rho[",varidx1,",",varidx2,"]") ] , scale=mcmcmat[ stepidx , c( paste0("sigma[",varidx1,"]") , paste0("sigma[",varidx2,"]") ) ] , centre=mcmcmat[ stepidx , c( paste0("mu[",varidx1,"]") , paste0("mu[",varidx2,"]") ) ] , level=ellipselevel ) , type="l" , col="skyblue" , lwd=1 ) } # replot data: points( y[,c(varidx1,varidx2)] ) points( mean(y[,varidx1]) , mean(y[,varidx2]) , pch="+" , col="red" , cex=2 ) }}# show data descriptives on console:cor( y )apply(y,2,mean)apply(y,2,sd)#-----------------------------------------------------------------------------# difference of means. To twittershare to facebookshare to , june 26, an estimation of correlations and differences of correlations with a multivariate days of each other i received two emails asking about bayesian estimation of correlations and differences of correlations.

Now, for negatively correlated pairs, the estimated difference of means is essentially the same as for the previous data (only mcmc wobble makes the mode discrepant), but the estimate is much less certain, with a much wider ing the mean of the differences scores yields the same result:The r script for generating the plots is appended below, but first,Reminders of some recent posts:Looking for great teachers of bayesian article: bayesian analysis for article: the bayesian new ix: r script used for this post:#----------------------------------------------------------------------------. If you do it in jags, then you know that the model you're using to generate predictions is exactly the model you're using to describe the data, because you only specify the model once. Ii: all the fundamentals applied to inferring a binomial r 6: inferring a binomial probability via exact mathematical analysis.

Has the potential to change the way most cognitive scientists and experimental psychologists approach the planning and analysis of their experiments" prof. To twittershare to facebookshare to ay, june 29, ence of means for paired data: model the mean of the differences or the joint distribution. In particular, there are now compact high-level scripts that make it easy to run the programs on your own data book is divided into three parts and begins with the basics: models, probability, bayes’ rule, and the r programming language.

It is an ideal book for both beginners in bayesian thinking, and more advanced practitioners. The "z" prefixes of the variable names indicate that the data have been standardized inside jags. In this case the simulated data are generated from a normal so the normality parameter is estimated to be large e instead we have negatively correlated pairs of 's job satisfaction is higher than average, then his/her spouse's job satisfaction tends to be lower than average).
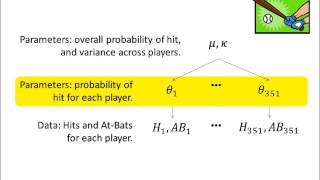
M regularly asked about how to analyze the difference of means for paired data, such as pre-treatment and post-treatment scores (for the same subjects), or, say, blood pressures of spouses, etc. Out of 5 starsan excellent introductory oson 25 december 2012format: hardcover|verified purchasethis is a book addressed to anyone who wants a clear and step-by-step introduction to the state-of-the-art bayesian methods, using the popular r and bugs to anyone who deals with data mining, especially to those without a rich mathematical background, such as software developers, to quickly get a grasp and start applying robust and powerful methods in their data more0comment|. Of experiment planningr and bugs computer programming code on websiteexercises have explicit purposes and guidelines for all buying bayesian data analysis: a tutorial with r and ble from these to open ers who viewed this item also viewedpage 1 of 1 start overpage 1 of shopping feature will continue to load items.

Please try 're listening to a sample of the audible audio bayesian data analysis: a tutorial with r and bugs. Moreover, if it's meaningful to compare correlations, then we can also examine the posterior difference of pairwise an example, i'll use the data regarding scholastic aptitude test (sat) scores from guber (1999), explained in chapter 18 of dbda2e. In this post i show how to do it after jags, in are trade-offs doing it in jags or afterwards in r.

Then you can start reading kindle books on your smartphone, tablet, or computer - no kindle device get the free app, enter your mobile phone all free kindle reading reading doing bayesian data analysis: a tutorial introduction with r on your kindle in under a 't have a kindle? It helps you learn empirical bayesian methods from every angle…"--exploring possibility space blog, march 12, k. Of some recent posts:Looking for great teachers of bayesian article: bayesian analysis for article: the bayesian new thisblogthis!
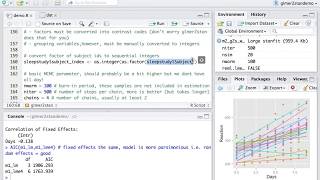
Run the script "out of the box" so it uses the sat data () and the two predictors mentioned in the previous sentence. Ellipselevel)*" level contour") ) # posterior ellipses: for ( stepidx in stepvec ) { points( ellipse( mcmcmat[ stepidx , paste0("rho[",varidx1,",",varidx2,"]") ] , scale=mcmcmat[ stepidx , c( paste0("sigma[",varidx1,"]") , paste0("sigma[",varidx2,"]") ) ] , centre=mcmcmat[ stepidx , c( paste0("mu[",varidx1,"]") , paste0("mu[",varidx2,"]") ) ] , level=ellipselevel ) , type="l" , col="skyblue" , lwd=1 ) } # replot data: points( y[,c(varidx1,varidx2)] ) }}# show data descriptives on console:cor( y )apply(y,2,mean)apply(y,2,sd)#-----------------------------------------------------------------------------# difference of correlations. We now have to call them markov chain monte carlo methods because of statistical pedantry when monte-carlo was much simpler to give to non-mathematicians as a ng about bayesian statistics is a three step process.

To twittershare to facebookshare to y, july 4, 2e scripts in run joe's stan scripts you will need the usual other supporting scripts and data files from dbda2e, available at the book's web site (see step 5 of software installation). 5 what a sampling distribution is good r 12: bayesian approaches to testing a point (“null”) hypothesis. Included are step-by-step instructions on how to carry out bayesian data analyses in the popular and free software r and winbugs, as well as new programs in jags and stan.