Statistical data analysis
Statistical le linear on: home > statistics tutorial overview > statistical tical data tanding statistical tical inference is based upon mathematical laws of probability. In a positively skewed distribution [figure 3], the mass of the distribution is concentrated on the left of the figure leading to a longer right 3curves showing negatively skewed and positively skewed distributioninferential statisticsin inferential statistics, data are analysed from a sample to make inferences in the larger collection of the population. Once you master these fundamental techniques for statistical data analysis, then you’re ready to advance to more powerful data analysis learn more about improving your statistical data analysis through powerful data visualization, click the button below to download our free guide, “5 tips for security data analysis” and start turning your abstract numbers into measurable y policysite mapdesign by hinge© big sky wikipedia, the free to: navigation, of a series on atory data analysis • information ctive data ptive statistics • inferential tical graphics • analysis • munzner • ben shneiderman • john w.

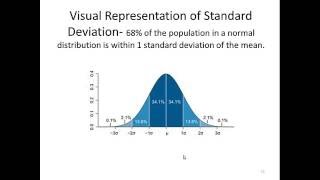
Hence, an adequate knowledge of statistics and the appropriate use of statistical tests are important. For example, regression analysis may be used to model whether a change in advertising (independent variable x) explains the variation in sales (dependent variable y). Standard standard deviation, often represented with the greek letter sigma, is the measure of a spread of data around the mean.

Hybrid hard disk drive is an electromechanical spinning hard disk that contains some amount of nand flash ational statistics & data ational statistics & data official journal of the network computational and methodological statistics (cmstatistics) and the international association of statistical computing (iasc). The journal consists of three refereed sections which are divided into the following subject areas:i) computational statistics - manuscripts dealing with: 1) the explicit impact of computers on statistical methodology (e. Customers specifying requirements and analysts performing the data analysis may consider these messages during the course of the -series: a single variable is captured over a period of time, such as the unemployment rate over a 10-year period.
Simplified formula for the f statistic is:where msb is the mean squares between the groups and msw is the mean squares within ed measures analysis of varianceas with anova, repeated measures anova analyses the equality of means of three or more groups. All are varieties of data integration is a precursor to data analysis, and data analysis is closely linked to data visualization and data dissemination. Formulas or models called algorithms may be applied to the data to identify relationships among the variables, such as correlation or causation.

An example is an application that analyzes data about customer purchasing history and recommends other purchases the customer might enjoy. These tests examine whether one instance of sample data is greater or smaller than the median reference testthis test examines the hypothesis about the median θ0 of a population. The median is not skewed by extreme values, but it is harder to use for further statistical mode is the most common value in a data set.

If only two categories exist (as in gender male and female), it is called as a dichotomous (or binary) data. In data analysis and statistics, you consider the result of a hypothesis test statistically significant if the results couldn’t have happened by random chance. Any anomalies within a given set of data cases with respect to a given relationship or expectation, e.

Data visualization may also be used to examine the data in graphical format, to obtain additional insight regarding the messages within the data. The data may also be collected from sensors in the environment, such as traffic cameras, satellites, recording devices, etc. As in the sign test, if there is an observed value that is equal to the reference value θ0, this observed value is eliminated from the on's rank sum test ranks all data points in order, calculates the rank sum of each sample and compares the difference in the rank -whitney testit is used to test the null hypothesis that two samples have the same median or, alternatively, whether observations in one sample tend to be larger than observations in the –whitney test compares all data (xi) belonging to the x group and all data (yi) belonging to the y group and calculates the probability of xi being greater than yi: p (xi > yi).

It is especially important to exactly determine the structure of the sample (and specifically the size of the subgroups) when subgroup analyses will be performed during the main analysis characteristics of the data sample can be assessed by looking at:Basic statistics of important ations and -tabulations[31]. The commonly used software systems are statistical package for the social sciences (spss – manufactured by ibm corporation), statistical analysis system ((sas – developed by sas institute north carolina, united states of america), r (designed by ross ihaka and robert gentleman from r core team), minitab (developed by minitab inc), stata (developed by statacorp) and the ms excel (developed by microsoft). Examples of discrete data are number of episodes of respiratory arrests or the number of re-intubations in an intensive care unit.
Sjr uses a similar algorithm as the google page rank; it provides a quantitative and a qualitative measure of the journal’s example article on lides are short, 5-minute presentations in which the author explains their paper in their own in brief authors co-submit and publish a data article in data in brief, it appears on sciencedirect linked to the original research article in this ctive map example article on application allows readers to interactively explore google maps (kml/kmz files) submitted with the article, and to download the original data ctive matlab figure example article on application allows readers to interactively explore matlab figures submitted with the article, and to download the original data ctive plot example article on application lets readers explore data and other quantitative results submitted with the article, providing insights into and access to data that is otherwise buried in sx authors co-submit and publish a method article in methodsx, it appears on sciencedirect linked to the original research article in this r code viewer presents computer code in the “r†language,Together with any relevant data files, for easy inspection with hing your article with us has many benefits, such as having access to a personal dashboard: citation and usage data on your publications in one place. For example, when analysts perform financial statement analysis, they will often recast the financial statements under different assumptions to help arrive at an estimate of future cash flow, which they then discount to present value based on some interest rate, to determine the valuation of the company or its stock. This might, for example, be men, women, and ‘no gender specified’, grouped by age categories 20–29, 30–39, 40–49 and 50– alternative to a histogram is a line chart, which plots each data point and joins them up with a line.

Should check the success of the randomization procedure, for instance by checking whether background and substantive variables are equally distributed within and across the study did not need or use a randomization procedure, one should check the success of the non-random sampling, for instance by checking whether all subgroups of the population of interest are represented in possible data distortions that should be checked are:Dropout (this should be identified during the initial data analysis phase). Also: problem jonathan koomey has recommended a series of best practices for understanding quantitative data. Some concrete conditions on attribute values, find data cases satisfying those data cases satisfy conditions {a, b, c...
